Are LLM merge rates not getting better?
https://entropicthoughts.com/no-swe-bench-improvementAnd even if we were to agree that that's a reasonable standard, GPT 5 shouldn't be included. There is only one datapoint for all OpenAI models. That data point more indicative of the performance of OpenAI models (and the harness used) than of any progression. Once you exclude it it matches what you would expect from a logistic model. Improvements have slowed down, but not stopped
1: https://metr.org/assets/images/many-swe-bench-passing-prs-wo...
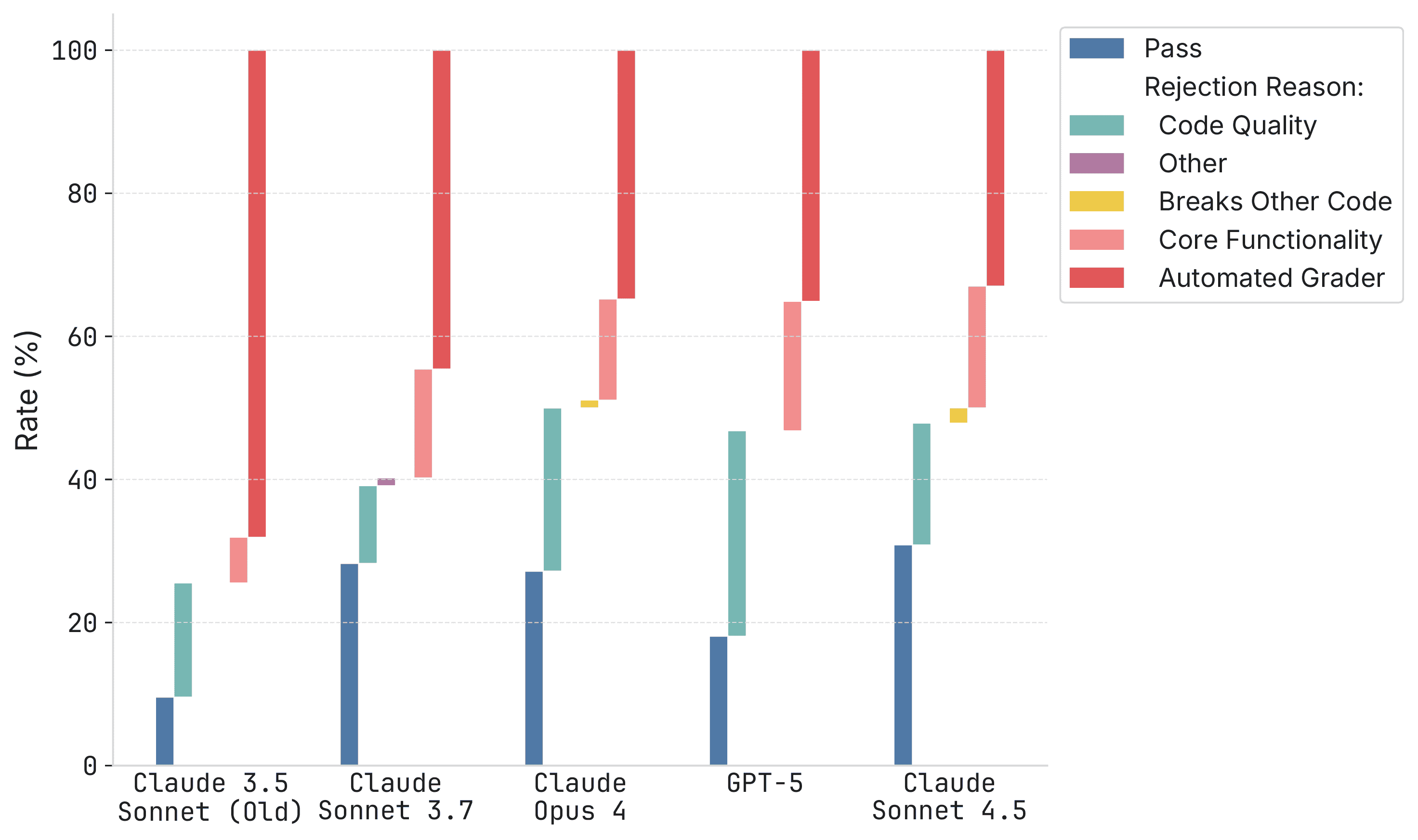{kind=link}
There are good reasons why they don't or can't do simple param upscaling anymore, but still, it makes me bearish on AGI since it's a slow, but massive shift in goal setting.
In practice this still doesn't mean 50 % of white collar can't be automated though.
It's notably lacking newer models (4.5 Opus, 4.6 Sonnet) and models from Gemini.
LLMs appear to naturally progress in short leaps followed by longer plateaus, as breakthroughs are developed such as chain-of-thought, mixture-of-experts, sub-agents, etc.
1) Something happened during 2025 that made the models (or crucially, the wrapping terminal-based apps like Claude Code or Codex) much better. I only type in the terminal anymore.
2) The quality of the code is still quite often terrible. Quadruple-nested control flow abounds. Software architecture in rather small scopes is unsound. People say AI is “good at front end” but I see the worst kind of atrocities there (a few days ago Codex 5.3 tried to inject a massive HTML element with a CSS before hack, rather than proprerly refactoring markup)
Two forces feel true simultaneously but in permanent tension. I still cannot make out my mind and see the synthesis in the dialectic, where this is truly going, if we’re meaningfully moving forward or mostly moving in circles.
On the other hand, LLMs tend to go for an average by their nature (if you squint enough). What's more common in their training data, it's more common in the output, so getting them better without fundamental changes, requires one to improve the training data on average too which is hard.
What did improve a lot is the tooling around them. That's gotten way better.
But LLMs are hamstrung by their harnesses. They are doing the equivalent of providing technical support via phone call: little to no context, and limited to a bidirectional stream of words (tokens). The best agent harnesses have the equivalent of vision-impairment accessibility interfaces, and even those are still subpar.
Heck, giving LLMs time to think was once a groundbreaking idea. Yesterday I saw Claude Code editing a file using shell redirects! It's barbaric.
I expect future improvements to come from harness improvements, especially around sub agents/context rollbacks (to work around the non-linear cost of context) and LLM-aligned "accessibility tools". That, or more synthetic training data.
Truth is I'm probably wrong. I should keep on testing ... but at the same time I precisely gave up because I didn't think the trend was fast enough to keep on investing on checking it so frequently. Now I just read this kind of post, ask around (mainly arguing with comments asking for genuine examples that should be "surprising" and kept on being disappointed) and that seems to be enough for a proxy.
I should though, as I mentioned in another comment, keep track of failed attempts.
PS: I check solely on self-hosted models (even if not on my machine but least on machines I could setup) because I do NOT trust the scaffolding around proprietary closed sources models. I can't verify that nobody is in the loop.
Assuming we get no better than opus 4.6, they're very capable. Even if they make up nonsense 5% of the time!
I think the only reasonable thing to read into is Sonnet 3.5 -> 3.7 -> 4.5. But yeah, you just can't draw a line through this thing.
I will die on the hill that LLMs are getting better, particularly Anthropic's releases since December. But I can't point at a graph to prove that, I'm just drawing on my personal experience. I do use Claude Code though, so I think a large part of the improvement comes from the harness.
Regardless I'm more inclined to believe that 4.5 was the point that people started using it after having given up on copy/pasting output in 2024. If you're going from chat to agentic level of interaction it's going to feel like a leap.
When you combine models with:
tool use
planning loops
agents that break tasks into smaller pieces
persistent context / repos
the practical capability jump is huge.
We still have tons of gaps about how to build and maintain code with AI, but LLM themselves getting better at an unbelievable pace, even with this kind of data analysis I’m surprised anyone can even question it.
It's my experience that opus 4, and then, particularly, 4.5, in Claude code, are head and shoulders above the competition.
I wrote an agentic coder years ago and it yielded trash. (Tried to make it do then what kiro does today).
The models are better. Now, caveat - I don't use anything but opus for coding - Sonnet doesn't do the trick. My experience with Codex and Gemini is that their top models are as good as Sonnet for coding...
So we got better in giving it the right context and tools to do the stuff we need to do but not the actual thinking improvements
What's been the game changer are tools like Claude Code. Automatic agentic tool loops purpose built for coding. This is what I have seen as the impetus for mainstream adoption rather than noticeable improvements in ability.
At the end of the day they still produce code that I need to manually review and fully understand before merging. Usually with a session of back-and-forth prompting or manual edits by me.
That was true 2 years ago, and it’s true now (except 2 years ago I was copy/pasting from the browser chat window and we have some nicer IDE integration now).
Because hype makes money.
That actually helps.
I mean, sure. but it's obvious in that graph that the single openai model is dragging down the right side. Wouldn't it be better to just stick to analyzing models from only one lab so that this was showing change over time rather than differences between models?
As they said, ragebait used to be believable.
So I’d say fairly flat commit acceptance numbers make sense even in the context of improving LLMs
There's only so much data to train on, and we are unlikely to see giant leaps in performance as we did in 2023/2024.
2026-27 will be the years of primarily ecosystem/agentic improvements and reducing costs.
Because it's not true. They have improved tremendously in the last year, but it looks like they've hit a wall in the last 3 months. Still seeing some improvements but mostly in skills and token use optimization.
> OpenAI’s leading researchers have not completed a successful full-scale pre-training run that was broadly deployed for a new frontier model since GPT-4o in May 2024 [1]
That's evidence against "intrinsically better". They've also trained on the entire internet - we only have 1 internet, so.
However, late 2024 was the introduction of o1 and early 2025 was Deepseek R1 and o3. These were definitely significant reasoning models - the introduction of test time compute and significant RL pipelines were here.
Mid 2025 was when they really started getting integrated with tool calling.
Late 2025 is when they really started to become agentic and integrate with the CLI pretty well (at least for me). For example, codex would at least try and run some smoke tests for itself to test its code.
In early 2026, the trend now appears to be harness engineering - as opposed to "context engineering" in 2025, where we had to preciously babysit 1 model's context, we make it both easier to rebuild context (classic CS trick btw: rebooting is easier than restoring stale state [2]) and really lean into raw cli tool calling, subagents, etc.
[1] https://newsletter.semianalysis.com/p/tpuv7-google-takes-a-s...
[2] https://en.wikipedia.org/wiki/Kernel_panic
FWIW, AI programming has still been as frustrating as it was when it was just TTC in 2025. Maybe because I don't have the "full harness" but it still has programming styles embedded such as silent fallback values, overly defensive programming, etc. which are obvoiusly gleaned from the desire to just pass all tests, rather than truly good programming design. I've been able to do more, but I have to review more slop... also the agents are really unpleasant to work with, if you're trying to have any reasonable conversation with them and not just delegate to them. It's as if they think the entire world revolves around them, and all information from the operator is BS, if you try and open a proper 2-way channel.
It seems like 2026 will go full zoom with AI tooling because the goal is to replace devs, but hopefully AI agents become actually nice to work with. Not sycophantic, but not passively aggressively arrogant either.
>To study how agent success on benchmark tasks relates to real-world usefulness, we had 4 active maintainers from 3 SWE-bench Verified repositories review 296 AI-generated pull requests (PRs). We had maintainers (hypothetically) accept or request changes for patches as well as provide the core reason they were requesting changes: core functionality failure, patch breaks other code or code quality issues.
I would also advise taking a look at the rejection reasons for the PRs. For example, Figure 5 shows two rejections for "code quality" because of (and I quote) "looks like a useless AI slop comment." This is something models still do, but that is also very easily fixable. I think in that case the issue is that the level of comment wanted hasn't been properly formalized in the repo and the model hasn't been able to deduce it from the context it had.
As for the article, I think mixing all models together doesn't make sense. For example, maybe a slope describe the increasing Claude Sonnet better than a step function.
I also wonder how much of the jump in early 2025 comes from cultural acceptance by devs, rather than an improvement in the tools themselves.
Examples from the last month: the agent found its own API keys in environment files after initially claiming it didn't have them (lesson: grep before asking). It caught itself about to run a destructive database migration on a shared production instance and stopped. It fixed 8 broken RSS feed configurations that had been silently failing for weeks without anyone noticing.
The pattern I've found: AI doesn't need to be perfect at writing code. It needs to be honest about what it doesn't know, aggressive about testing its own work, and operating under clear constraints about what's destructive vs. safe. We maintain a file called AGENTS.md with "sacred rules" — things the agent can never do without explicit approval. Database migrations, pricing changes, anything with --accept-data-loss.
The "no LLM" stance makes sense if you don't have guardrails. With the right constraints, AI-assisted code is faster AND safer than solo human development — because the agent never gets tired, never rushes before a deadline, and never thinks "I'll test that later."